How to Automate IBM i with Git and Modern DevOps Tools
Get Full Lifecycle DevOps Automation using Open-Source DevOps Tools
In my many recent conversations with IBM i users regarding modernization, one recurring theme has stood out: a strong desire to harness the power of Git for IBM i source code version control. However, many of these users have used IBM i native change management tools for a long time and rely on their IBM i specific process automation features. They need assurance that adopting Git won’t mean sacrificing critical automation such as moving code through a well-defined lifecycle, ensuring proper builds at every stage (using the right create options and library lists), deploying code across IBM i partitions/machines, and meeting audit requirements like separation of duties.
The great news? Git excels at version control, and when developers combine it with modern DevOps tools like Jenkins, Azure Pipelines, and GitHub Actions, they gain access to a comprehensive automation ecosystem. These tools can seamlessly wrap around Git, and when paired with Eradani DevOps, they enable powerful lifecycle automation that simplifies code movement, enforces governance, and integrates with existing workflows—bringing IBM i development into the modern DevOps era.
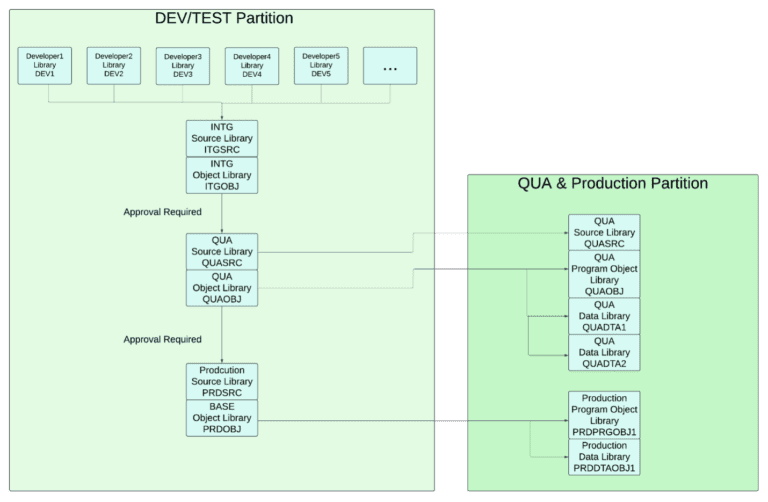
Let’s take a look at how that might work. Suppose you have an environment like the one in the diagram below. It shows a simplified version of a common setup for IBM i users:
Sample IBM i code change workflow.
In this example:
Developers make changes, create objects, and unit test in their own library.
The team promotes changes to an integration test environment where they test multiple developers’ changes together. They might initiate another create in this environment.
The QA team moves the changes to their environment for final testing.
Each QUA tester in this sample has their own set of test data in their own data libraries.
The QUA Manager must approve the changes moving to QUA.
In this example, the QUA libraries also exist on a separate QUA partition, so the changes need to be deployed from one partition (or machine) to another.
Finally, the changes move to Production.
The deployment team moves only the objects to the Production partition.
The team must gather approvals before deploying the changes to Production.
Developers must run successful code scans before deploying the changes to Production.
The challenges for IBM i users include:
Keeping track of which version of the code is at each stage of the lifecycle.
Automating the creates of the changed code and the creates of the dependencies on the changed code at each stage where a compile is required.
Moving the code between the Git repository and the IBM i libraries.
Enforcing the process (DEV to Integration to QUA to Production).
Gathering approvals.
Deploying the changed objects from one partition to others.
Keeping Track of the Versions at Each Stage
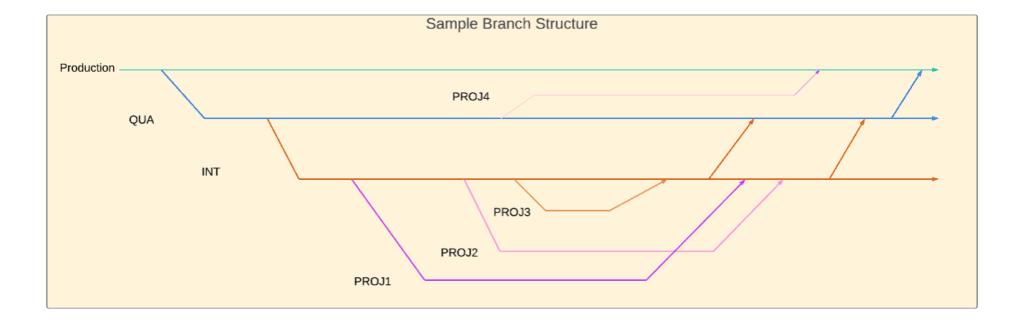
Fortunately, Git excels at version management and change tracking. Its ability to “branch” versions makes it easy to manage multiple versions of your application simultaneously. For our example, you could set up a branch structure in Git like this:
In this branching structure, each branch represents a view of the Git repository that shows the user the appropriate version of each source member for each environment in the lifecycle. Each stage and each project is represented by its own branch, allowing each branch to be worked with as needed.
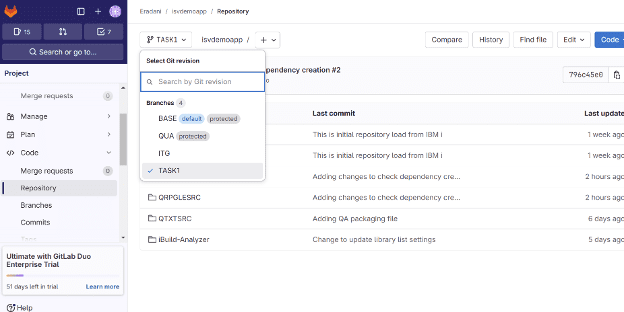
Using your Git tools, you can view the source for any version of your application. Here is a sample view from GitLab:
In this view, I have four branches: BASE (Production), QUA, ITG, and TASK1. This view currently shows the TASK1 branch. If the user were to drill down into the source code for any object, they would see the version of the source code for that branch (or environment). I can even compare branches to see the code changes between them. It is a very powerful way to see exactly what is running in each stage and how the versions are different.
Automating Object Creation at Each Stage of the Lifecycle & Moving the Code Between the Git Repository and the IBM i Libraries
To create the objects, you simply need to switch to the appropriate branch and do a Git pull operation to pull the source code from the Git repository to the appropriate IBM i library. Here is where Eradani DevOps can help. Eradani provides a Git pull function that will pull the code from a Git repository like GitHub, GitLab, Bitbucket, or just a local Git repository on your IBM i and place the changed code into the appropriate library (libraries) for that branch. Eradani’s iBuild module will then perform the creates for all the changed objects and all the objects dependent on what has changed.
As code moves from branch to branch in the Git repository (eg. TASK, ITG, QUA, PRODUCTION), Eradani DevOps will keep the associated IBM i libraries up to date. At each stage, Eradani DevOps can build the objects, create the dependent objects, and distribute the built objects to any number of target locations.
Enforcing the Defined Move-to-Production Process
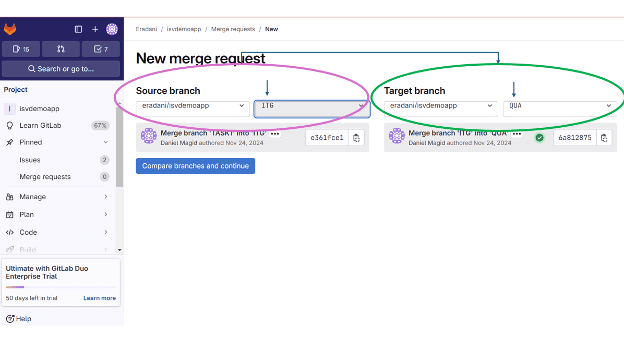
Users can configure the Git pipeline management functions to enforce a defined move to production process that requires changes to pass through the appropriate stages before getting to Production. Changes can move from branch to branch through a Git push operation in which an authorized user pushes their changes into another branch or via a Git pull operation in which code is pulled from one branch to the next branch. Approvals and other required steps can be implemented using a “pull request”. A pull request is a request to move code from one branch (eg. Integration Test) to another branch (eg. QUA). Fulfillment of a pull request can require functions like code scans, automated tests, code reviews, and approvals as code moves from stage to stage. In this example, using GitLab, code must go from the Task branch to Integration Test, to QUA, and then to the Base Production code. When you initiate a pull request from Integration Test, the system automatically fills in the box that says the target branch is QUA, ensuring the code follows the right path.
Based on our configuration, GitLab automatically sets the target branch for a Pull Request based on the source branch of the request. This ensures that changes move through the lifecycle stages in the appropriate order.
Gathering Approvals
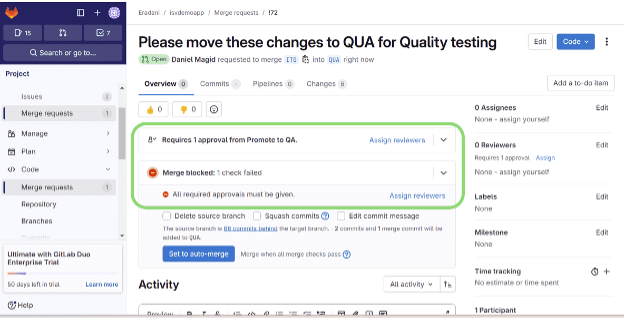
For each merge operation between branches, users can set approval rules. Without the required approvals, the merge cannot be performed. In this screenshot, you can see that the merge has been blocked:
In this example, the merge process is blocked because the approvals have not been gathered. This case requires ALL approvals to be completed. Administrators can also configure rules to require approval from only some of the designated reviewers instead.
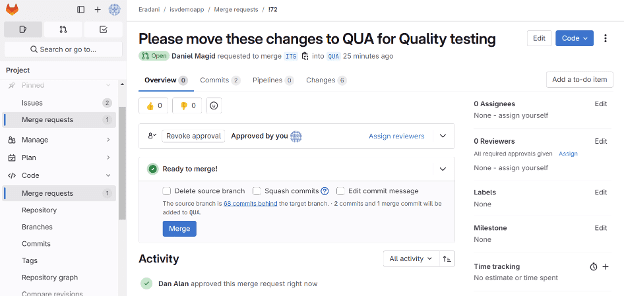
Once the approval(s) is given:
Following the approval(s) of the Pull Request, the status goes to “Ready to merge”. An authorized user can now run the merge. The system creates a log entry recording each approval.
Automating the Promotion and Deployment Process
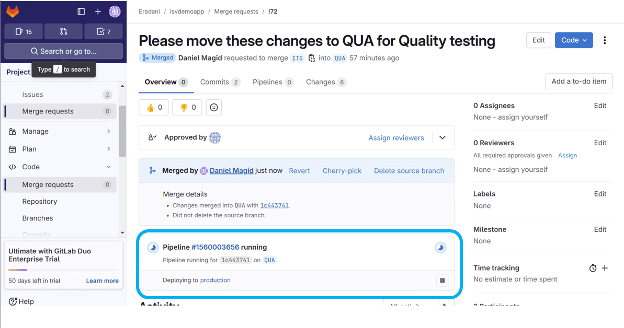
The Pull Request can be used to automate a wide variety of DevOps processes. You can use the Pull Request to initiate the promotion and deployment of the changes. Below is an example of an automation in which the Pull Request process pulls the code from the GitLab repository to the appropriate IBM i libraries for the QUA stage, builds the objects, and then deploys the objects to the final QUA target location(s).
Automated pipeline is running.
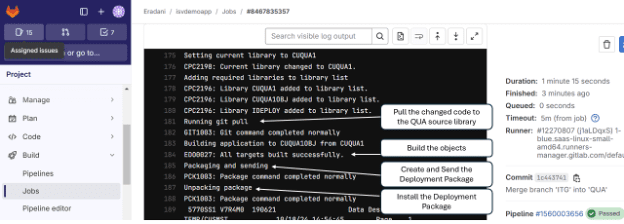
The system keeps you up to date on the progress of the automated process for moving changes to QUA:
The above image shows the changes as they are successfully transferred from the cloud repository to the IBM i library(ies), the creation of the changed objects and dependent objects, the packaging and sending of the savefile and the installation of the changes in the target location.
As you can see, with the help of Eradani DevOps, it is definitely possible to set up a standard automated IBM i DevOps workflow using modern open-source tools like Git and GitLab. And we have barely scratched the surface of the benefits you can get from moving to open-source DevOps for your IBM i code. See our other blog posts for how these tools can simplify audits, speed up the time to market for software changes, increase the visibility of your changes, and provide a myriad of integrations with powerful open-source DevOps tools. If you want to learn more about how you can move to open-source DevOps with Eradani Connect, reach out to us at here!
IBM i DevOps Automation Demo: A step-by-step walkthrough of managing code changes through development, integration, QA, and deployment stages using Git, GitLab, and Eradani DevOps tools. Presented by Dan Maggid, CEO of Eradani, this demonstration shows how to modernize traditional IBM i development with open-source DevOps practices, including source control, automated builds, approval workflows, and continuous deployment.
Dan has spent over thirty years leading companies that help customers implement new technologies in legacy environments. Previously, Dan led worldwide software development groups that built highly successful modernization and DevOps tools and was the CEO of Aldon, the leading provider of DevOps tools to the IBM i marketplace. To learn more about Eradani’s offerings, reach out to us today!
Get the latest Eradani Blog posts sent to your email.