Now that so many IBM i users are adopting APIs to automate their communications with customers and partners, we are receiving many questions about how to manage the traffic. In my last blog, I talked about monitoring and how to check the health of your APIs. In this blog, we will talk about throttling and rate limits to control the volume of API calls reaching your system.
First a note on definitions. When you look online for the meaning of throttling and rate limiting for APIs, you will find several different definitions. Some use throttling and rate limits interchangeably. Others refer to throttling as a server-side function to limit incoming calls while rate limits are defined as client-side functions to limit outgoing calls. While still others refer to rate limits as setting hard limits on the number of requests while throttling is used to manage the flow of API calls over time to eliminate spikes. In this blog, I am going to use the term throttling and then identify whether I am talking about server-side or client-side.
Server-side Throttling is what the API provider does to limit the number of API calls it will accept. It is a server-side function that throws a throttling error if a user exceeds the permitted number of calls.
Client-side Throttling is something the API consumer does to ensure that they are not sending too many calls to an API. It is a client-side function that prevents you from hitting the throttling limits set by your API provider (or to control your costs if you are being charged for API access).
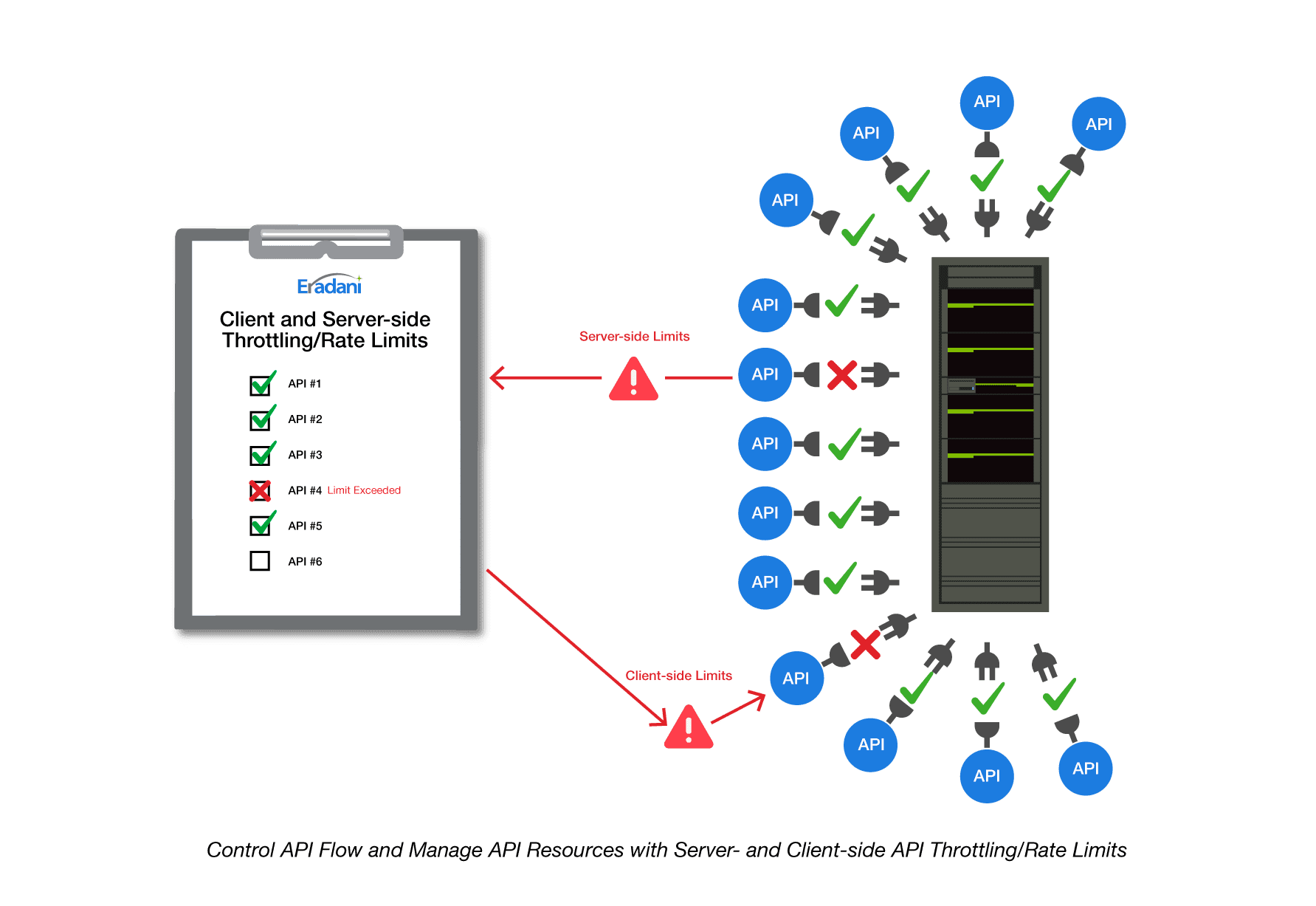
Server-side Throttling
Why would you want to limit the number of API calls?
Since APIs are meant to make it easy for customers and partners to communicate with your applications, why would you want to limit them? There are multiple reasons why this is a good idea:
- Catch looping API calls that are sending unplanned volumes of calls
- Ensure your API capacity is shared and no user is monopolizing your API capacity
- Rapidly identify and stop Distributed Denial of Service attacks
- Monetize your APIs
You can throttle API calls using a variety of criteria. You can throttle by the origin IP address, the user, the origin domain, by your API endpoint, and other criteria. Eradani Connect users can throttle by application and by groups of APIs.
Throttling by Users will help you if one of your clients has written an API calling program with an uncontrolled loop. This kind of mistake can cause their system to make hundreds or even thousands of unplanned API calls. Your throttling system can catch that error and slow down their access or even cut it off altogether until the problem is fixed.
If you have limited resources for supporting your APIs and you want to ensure those resources are shared equitably among your consumers, you can set blanket limits for everyone. If a particular user is making an unusually high number of calls, they will get a throttling message telling them that their access is being slowed or cut off (you can create the content of the message to be as polite as you would like). This technique will ensure that all your users have reasonable access to your APIs.
One of the key benefits of monitoring and throttling is to aid in preventing potential Distributed Denial of Service (DDoS) attacks. A DDoS attack occurs when a malicious actor attempts to prevent legitimate users from accessing your system by overwhelming your APIs with vast numbers of calls from many origins simultaneously. With properly implemented throttling as part of your DDoS prevention strategy, you can automatically cut off these unwelcome users.
Many of our customers see API access to some of their systems as a potential new revenue source. Throttling by users allows you to provide levels of access based on how much volume the consumer has licensed.
Client-side Throttling
With client-side throttling, you as an API consumer can control the flow of your API calls. You might use throttling to:
- Comply with the throttling limits of your API provider
- Control your costs for API calls that are licensed by volume
Most of the publicly available APIs (Google, Amazon, Twitter, etc.) have set throttling limits on the calls you can make to their APIs. To ensure you don’t unexpectedly get cut off from their functions, you might want to implement rate limiting throttles that match their throttling limits on your API calls.
Many API providers charge for API access based on volumes (Twilio, Google, Amazon, Microsoft, etc.) You can use client-side throttling to manage your budget and ensure you don’t get surprised by unexpectedly high API charges.

Google Maps pricing for API access
With both server-side and client-side throttling there are two different important measurements:
- Burst limits – burst limits are limits on large numbers of API calls in short periods of time. These are usually measured in calls per second. They are meant to control spikes in API call volume
- Flow limits – flow limits are limits on how many calls you can make over longer periods of time. These might be limits on the calls per day, week or month.
Both kinds of limits can be enforced with throttling with server and client-side throttling.
If you run into a throttling or rate limiting error, you need to have a retry strategy. The retry strategy determines how long your system will wait before resubmitting a denied request. The most popular technique is “exponential backoff”. With exponential backoff, the API system retries the call with an exponentially increasing delay between calls. For example, you wait 2 seconds after the first failure, then 4 seconds after the second, 8 seconds after the third, etc. until you reach some defined limit before sending back a failure message to the calling program. The idea is that you are testing for the reset time on the limit you are hitting.
Throttling and exponential backoff are good reasons for building your APIs in open source languages like JavaScript or Python. These languages already have support for throttling, retries and exponential backoff built into their API frameworks. Many of the API providers include these functions in their JavaScript and Python SDKs. Without these, you will need to code the functions yourself from scratch.
If you would like to learn more about how to easily add server and client-side throttling to your API infrastructure, reach out to us at: [email protected] or through our website. We look forward to hearing from you!